|
|
||
|---|---|---|
| avro | ||
| config | ||
| docs | ||
| kafka-connect | ||
| notebooks | ||
| .env | ||
| .gitignore | ||
| README.md | ||
| docker-compose.yml | ||
| kafkaproducer.py | ||
| mastodonlisten.py | ||
| requirements.txt | ||
README.md
Mastodon usage - counting toots with DuckDB
Mastodon is a decentralized social networking platform. Mastodon users are members of a specific Mastodon server, and servers are capable of joining other servers to form a global (or at least federated) social network.
I wanted to start exploring Mastodon usage, and perform some exploratory data analysis of user activity, server popularity and language usage. You may want to jump straight to the data analysis
Tools used
- Mastodon.py - Python library for interacting with the Mastodon API
- Apache Kafka - distributed event streaming platform
- DuckDB - in-process SQL OLAP database and the HTTPFS DuckDB extension for reading remote/writing remote files of object storage using the S3 API
- MinIO - S3 compatible server
- Seaborn - visualization library
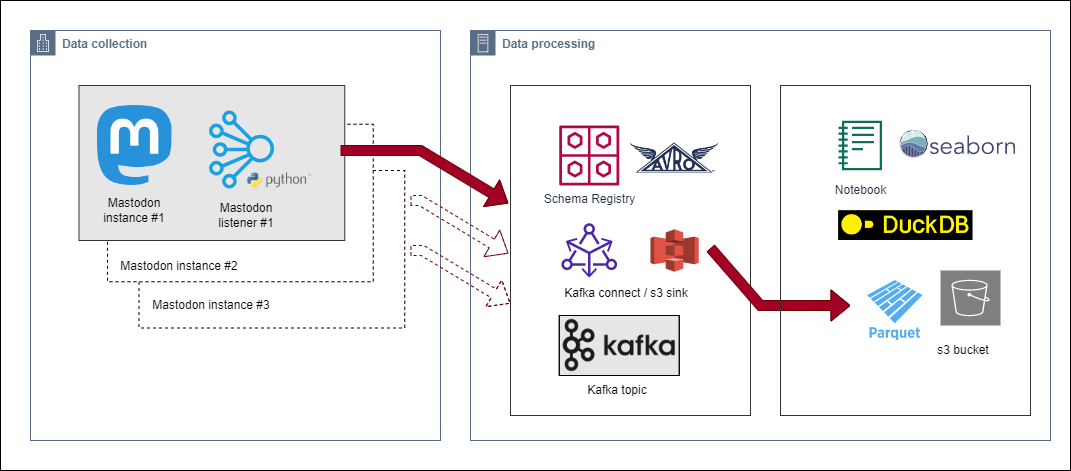
Data processing
We will us Kafka as distributed stream processing platform to collect data from multiple instances. To run Kafka, Kafka Connect (with the S3 sink connector) and schema registry (to support AVRO serialisation) and MinIO setup containers with this command
docker-compose up -d
Data collection
Setup virtual python environment
Create a virtual python environment to keep dependencies separate. The venv module is the preferred way to create and manage virtual environments.
python3 -m venv env
Before you can start installing or using packages in your virtual environment you’ll need to activate it.
source env/bin/activate
pip install --upgrade pip
pip install -r requirements.txt
Federated timeline
These are the most recent public posts from people on this and other servers of the decentralized network that this server knows about.
Mastodon listener
The python mastodonlisten application listens for public posts to the specified server, and sends each toot to Kafka. You can run multiple Mastodon listeners, each listening to the activity of different servers
python mastodonlisten.py --baseURL https://mastodon.social --enableKafka
Testing producer (optional)
As an optional step, you can check that AVRO messages are being written to kafka
kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic mastodon-topic --from-beginning
Kafka Connect
To load the Kafka Connect config file run the following
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/mastodon-sink-s3/config -d '@./config/mastodon-sink-s3-minio.json'
Open s3 browser
Go to the MinIO web browser http://localhost:9001/
- username
minio - password
minio123
Data analysis
Now we have collected a week of Mastodon activity, let's have a look at some data. These steps are detailed in the notebook
Query parquet files directly from s3 using DuckDB
Load the HTTPFS DuckDB extension for reading remote/writing remote files of object storage using the S3 API
INSTALL httpfs;
LOAD httpfs;
set s3_endpoint='localhost:9000';
set s3_access_key_id='minio';
set s3_secret_access_key='minio123';
set s3_use_ssl=false;
set s3_url_style='path';
And you can now query the parquet files directly from s3
select *
from read_parquet('s3://mastodon/topics/mastodon-topic/partition=0/*');
Daily Mastodon usage
We can query the mastodon_toot table directly to see the number of toots, users each day by counting and grouping the activity by the day
We can use the mode aggregate function to find the most frequent "bot" and "not-bot" users to find the most active Mastodon users
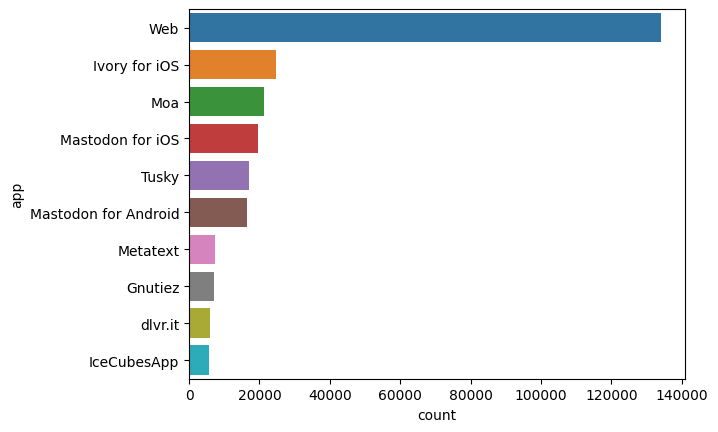
The Mastodon app landscape
What clients are used to access mastodon instances. We take the query the mastodon_toot table, excluding "bots" and load query results into the mastodon_app_df Panda dataframe. Seaborn is a visualization library for statistical graphics in Python, built on the top of matplotlib. It also works really well with Panda data structures.
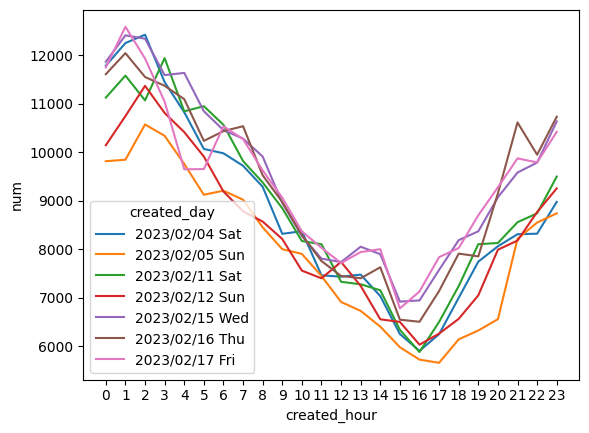
Time of day Mastodon usage
Let's see when Mastodon is used throughout the day and night. I want to get a raw hourly cound of toots each hour of each day. We can load the results of this query into the mastodon_usage_df dataframe
Language usage
A wildly inaccurate investigation of language tags
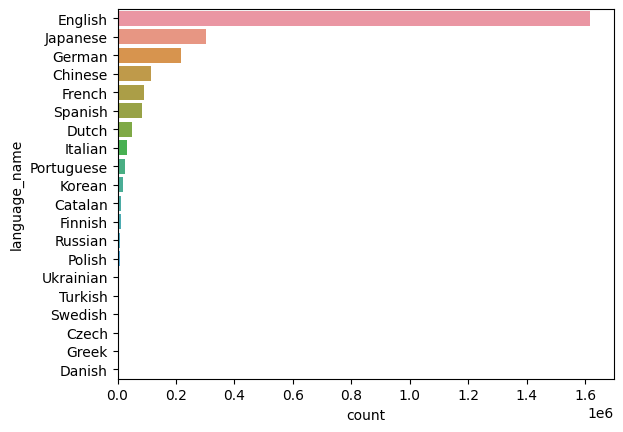
Language density
A wildly inaccurate investigation of language tags
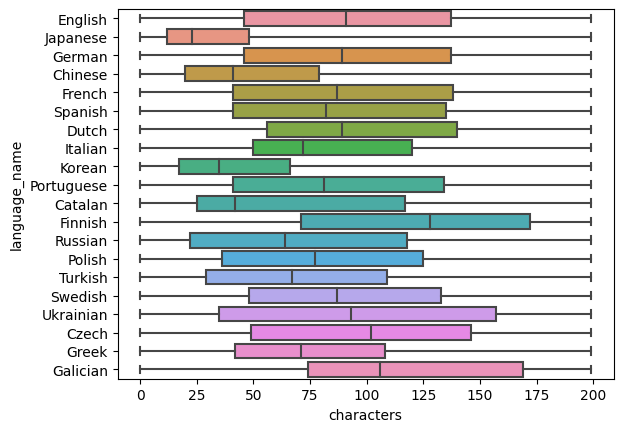
Optional steps
Cleanup of virtual environment
If you want to switch projects or otherwise leave your virtual environment, simply run:
deactivate
If you want to re-enter the virtual environment just follow the same instructions above about activating a virtual environment. There’s no need to re-create the virtual environment.