kopia lustrzana https://github.com/thinkst/zippy
Porównaj commity
3 Commity
6189edf770
...
2954176173
| Autor | SHA1 | Data |
|---|---|---|
|
|
2954176173 | |
|
|
1e3ae4e9aa | |
|
|
81bdb8e5dd |
21
README.md
21
README.md
|
|
@ -6,21 +6,23 @@ its training data to calculate the probability of each word given the preceeding
|
|||
the more high-probability tokens are more likely to be AI-originated. Techniques and tools in this repo are looking for
|
||||
faster approximation to be embeddable and more scalable.
|
||||
|
||||
## LZMA compression detector (`zippy.py` and `nlzmadetect`)
|
||||
## Compression-based detector (`zippy.py` and `nlzmadetect`)
|
||||
|
||||
ZipPy uses the LZMA compression ratios as a way to indirectly measure the perplexity of a text.
|
||||
ZipPy uses either the LZMA or zlib compression ratios as a way to indirectly measure the perplexity of a text.
|
||||
Compression ratios have been used in the past to [detect anomalies in network data](http://owncloud.unsri.ac.id/journal/security/ontheuse_compression_Network_anomaly_detec.pdf)
|
||||
for intrusion detection, so if perplexity is roughly a measure of anomalous tokens, it may be possible to use compression to detect low-perplexity text.
|
||||
LZMA creates a dictionary of seen tokens, and then uses though in place of future tokens. The dictionary size, token length, etc.
|
||||
LZMA and zlib creates a dictionary of seen tokens, and then uses though in place of future tokens. The dictionary size, token length, etc.
|
||||
are all dynamic (though influenced by the 'preset' of 0-9--with 0 being the fastest but worse compression than 9). The basic idea
|
||||
is to 'seed' an LZMA compression stream with a corpus of AI-generated text (`ai-generated.txt`) and then measure the compression ratio of
|
||||
is to 'seed' a compression stream with a corpus of AI-generated text (`ai-generated.txt`) and then measure the compression ratio of
|
||||
just the seed data with that of the sample appended. Samples that follow more closely in word choice, structure, etc. will acheive a higher
|
||||
compression ratio due to the prevalence of similar tokens in the dictionary, novel words, structures, etc. will appear anomalous to the seeded
|
||||
dictionary, resulting in a worse compression ratio.
|
||||
|
||||
### Current evaluation
|
||||
|
||||
Some of the leading LLM detection tools are ~~[OpenAI's model detector (v2)](https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)~~, [GPTZero](https://gptzero.me/), [CrossPlag's AI detector](https://crossplag.com/ai-content-detector/), and [Roberta](https://huggingface.co/roberta-base-openai-detector). Here are each of them compared with the LZMA detector across the test datasets:
|
||||
Some of the leading LLM detection tools are:
|
||||
~~[OpenAI's model detector (v2)](https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)~~, [Content at Scale](https://contentatscale.ai/ai-content-detector/), [GPTZero](https://gptzero.me/), [CrossPlag's AI detector](https://crossplag.com/ai-content-detector/), and [Roberta](https://huggingface.co/roberta-base-openai-detector).
|
||||
Here are each of them compared with both the LZMA and zlib detector across the test datasets:
|
||||
|
||||
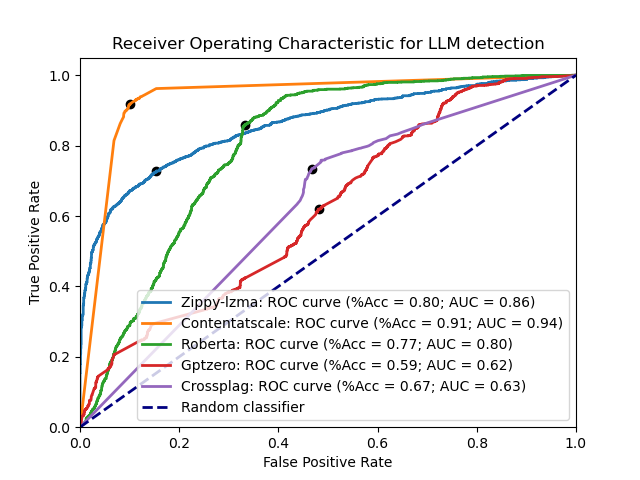
|
||||
|
||||
|
|
@ -29,14 +31,15 @@ Some of the leading LLM detection tools are ~~[OpenAI's model detector (v2)](htt
|
|||
ZipPy will read files passed as command-line arguments, or will read from stdin to allow for piping of text to it.
|
||||
```
|
||||
$ python3 zippy.py -h
|
||||
usage: zippy.py [-h] [-s | sample_files ...]
|
||||
usage: zippy.py [-h] [-e {zlib,lzma}] [-s | sample_files ...]
|
||||
|
||||
positional arguments:
|
||||
sample_files Text file(s) containing the sample to classify
|
||||
sample_files Text file(s) containing the sample to classify
|
||||
|
||||
options:
|
||||
-h, --help show this help message and exit
|
||||
-s Read from stdin until EOF is reached instead of from a file
|
||||
-h, --help show this help message and exit
|
||||
-e {zlib,lzma} Which compression engine to use: lzma or zlib
|
||||
-s Read from stdin until EOF is reached instead of from a file
|
||||
$ python3 zippy.py samples/human-generated/about_me.txt
|
||||
samples/human-generated/about_me.txt
|
||||
('Human', 0.06013429262166636)
|
||||
|
|
|
|||
{kind=link}
Plik binarny nie jest wyświetlany.
|
Przed Szerokość: | Wysokość: | Rozmiar: 78 KiB Po Szerokość: | Wysokość: | Rozmiar: 86 KiB |
File diff suppressed because one or more lines are too long
|
|
@ -25,6 +25,12 @@
|
|||
document.getElementById("addlp").hidden = false;
|
||||
console.log("Processing " + ilen + " bytes took " + (end - start) + " ms");
|
||||
}
|
||||
|
||||
async function ZLIB_compress(s) {
|
||||
const blobs = new Blob([s]).stream();
|
||||
const out = await (new Response(blobs.pipeThrough(new CompressionStream('deflate-raw'))).blob());
|
||||
return new Uint8Array(await out.arrayBuffer());
|
||||
}
|
||||
</script>
|
||||
<script src="./src/nlzmadetect.js" type="application/javascript"></script>
|
||||
<div id="footer" style="text-align: center; font-family: Arial, Helvetica, sans-serif;">
|
||||
|
|
|
|||
|
|
@ -1,43 +1,58 @@
|
|||
when defined(c):
|
||||
import std/[re, threadpool, encodings]
|
||||
import std/[re, encodings]
|
||||
import lzma
|
||||
when defined(js):
|
||||
import std/[jsffi, jsre]
|
||||
import dom
|
||||
import std/math
|
||||
import std/[math, async]
|
||||
import strutils
|
||||
when isMainModule and defined(c):
|
||||
import std/[parseopt, os]
|
||||
|
||||
when defined(js) and not defined(extension):
|
||||
import dom
|
||||
var local_prelude : string = ""
|
||||
when defined(extension):
|
||||
var local_prelude {.exportc.} : cstring = ""
|
||||
|
||||
type
|
||||
Engine = enum
|
||||
LZMAEngine, ZLibEngine
|
||||
|
||||
var COMPRESSION_PRESET {.exportc.} = 2.int32
|
||||
const SHORT_SAMPLE_THRESHOLD = 350
|
||||
|
||||
const ACTIVE_ENGINE = Engine.LZMAEngine
|
||||
|
||||
const PRELUDE_FILE = "../../ai-generated.txt"
|
||||
const PRELUDE_STR = staticRead(PRELUDE_FILE)
|
||||
proc compress_str(s : string, preset = COMPRESSION_PRESET): float64
|
||||
var PRELUDE_RATIO = compress_str("")
|
||||
const PRELUDE_STR {.exportc.} = staticRead(PRELUDE_FILE)
|
||||
proc compress_str(s : string, preset = COMPRESSION_PRESET): Future[float64] {.async.}
|
||||
var PRELUDE_RATIO = 0.0
|
||||
|
||||
when defined(js):
|
||||
var console {.importc, nodecl.}: JsObject
|
||||
when not defined(extension):
|
||||
proc getLocalStorageItem(key : cstring) : JsObject {.importjs: "localStorage.getItem(#)".}
|
||||
proc setLocalStorageItem(key : cstring, val : cstring) {.importjs: "localStorage.setItem(#, #)".}
|
||||
proc compress(str : cstring, mode : int) : seq[byte] {.importjs: "LZMA.compress(#, #)".}
|
||||
console.log("Initialized with a prelude compression ratio of: " & $PRELUDE_RATIO)
|
||||
proc lzma_compress(str : cstring, mode : int) : seq[byte] {.importjs: "LZMA.compress(#, #)".}
|
||||
proc zlib_compress(str : cstring) : Future[seq[byte]] {.importjs: "ZLIB_compress(#)", async.}
|
||||
|
||||
proc init() {.async.} =
|
||||
PRELUDE_RATIO = await compress_str("")
|
||||
when defined(js):
|
||||
console.log("Initialized " & $ACTIVE_ENGINE & " with a prelude compression ratio of: " & $PRELUDE_RATIO)
|
||||
|
||||
discard init()
|
||||
# Target independent wrapper for LZMA compression
|
||||
proc ti_compress(input : cstring, preset: int32, check: int32): seq[byte] =
|
||||
proc ti_compress(input : cstring, preset: int32, check: int32): Future[seq[byte]] {.async.} =
|
||||
when defined(c):
|
||||
return compress(input, preset, check)
|
||||
when defined(js):
|
||||
return compress(input, preset)
|
||||
when not defined(c):
|
||||
when ACTIVE_ENGINE == Engine.ZLibEngine:
|
||||
return await zlib_compress(input)
|
||||
when ACTIVE_ENGINE == Engine.LZMAEngine:
|
||||
return lzma_compress(input, preset)
|
||||
|
||||
proc compress_str(s : string, preset = COMPRESSION_PRESET): float64 =
|
||||
proc compress_str(s : string, preset = COMPRESSION_PRESET): Future[float64] {.async.} =
|
||||
when defined(c):
|
||||
let in_len = PRELUDE_STR.len + s.len
|
||||
var combined : string = PRELUDE_STR & s
|
||||
|
|
@ -50,12 +65,12 @@ proc compress_str(s : string, preset = COMPRESSION_PRESET): float64 =
|
|||
var combined : string = PRELUDE_STR & local_prelude & s
|
||||
let nonascii = newRegExp(r"[^\x00-\x7F]")
|
||||
combined = $combined.cstring.replace(nonascii, "")
|
||||
let out_len = ti_compress(combined.cstring, preset, 0.int32).len
|
||||
let out_len = (await ti_compress(combined.cstring, preset, 0.int32)).len
|
||||
return out_len.toFloat / in_len.toFloat
|
||||
|
||||
proc score_string*(s : string, fuzziness : int): (string, float64) =
|
||||
proc score_string*(s : string, fuzziness : int): Future[(string, float64)] {.async.} =
|
||||
let
|
||||
sample_ratio = compress_str(s)
|
||||
sample_ratio = await compress_str(s)
|
||||
delta = PRELUDE_RATIO - sample_ratio
|
||||
var determination = "AI"
|
||||
if delta < 0:
|
||||
|
|
@ -69,13 +84,13 @@ proc score_string*(s : string, fuzziness : int): (string, float64) =
|
|||
return (determination, abs(delta) * 100.0)
|
||||
|
||||
when defined(c):
|
||||
proc score_chunk(chunk : string, fuzziness : int): float64 =
|
||||
var (d, s) = score_string(chunk, fuzziness)
|
||||
proc score_chunk(chunk : string, fuzziness : int): Future[float64] {.async.} =
|
||||
var (d, s) = await score_string(chunk, fuzziness)
|
||||
if d == "AI":
|
||||
return -1.0 * s
|
||||
return s
|
||||
|
||||
proc run_on_text_chunked*(text : string, chunk_size : int = 1024, fuzziness : int = 3): (string, float64) =
|
||||
proc run_on_text_chunked*(text : string, chunk_size : int = 1024, fuzziness : int = 3): Future[(string, float64)] {.async.} =
|
||||
var inf : string = text
|
||||
when defined(c):
|
||||
inf = replace(inf, re" +", " ")
|
||||
|
|
@ -102,22 +117,8 @@ proc run_on_text_chunked*(text : string, chunk_size : int = 1024, fuzziness : in
|
|||
|
||||
var scores : seq[(string, float64)] = @[]
|
||||
|
||||
when defined(c):
|
||||
var flows : seq[FlowVar[float64]] = @[]
|
||||
for c in chunks:
|
||||
flows.add(spawn score_chunk(c, fuzziness))
|
||||
|
||||
for f in flows:
|
||||
let score = ^f
|
||||
var d : string = "Human"
|
||||
if score < 0.0:
|
||||
d = "AI"
|
||||
scores.add((d, score * -1.0))
|
||||
else:
|
||||
scores.add((d, score))
|
||||
when defined(js):
|
||||
for c in chunks:
|
||||
scores.add(score_string(c, fuzziness))
|
||||
for c in chunks:
|
||||
scores.add(await score_string(c, fuzziness))
|
||||
|
||||
var ssum : float64 = 0.0
|
||||
for s in scores:
|
||||
|
|
@ -154,9 +155,11 @@ when defined(c) and isMainModule:
|
|||
quit 0
|
||||
for fn in filenames:
|
||||
if fileExists(fn):
|
||||
proc print_results(score : Future[(string, float64)]) =
|
||||
let (d, s) = score.read()
|
||||
echo "(" & d & ", " & $s.formatFloat(ffDecimal, 8) & ")"
|
||||
echo fn
|
||||
let (d, s) = run_on_text_chunked(readFile(fn))
|
||||
echo "(" & d & ", " & $s.formatFloat(ffDecimal, 8) & ")"
|
||||
run_on_text_chunked(readFile(fn)).addCallback(print_results)
|
||||
|
||||
when defined(js) and isMainModule:
|
||||
when not defined(extension):
|
||||
|
|
@ -164,8 +167,7 @@ when defined(js) and isMainModule:
|
|||
document.getElementById("preset_value").value = ($COMPRESSION_PRESET).cstring
|
||||
if getLocalStorageItem("local_prelude") != jsNull:
|
||||
local_prelude = $(getLocalStorageItem("local_prelude").to(cstring))
|
||||
PRELUDE_RATIO = compress_str("")
|
||||
console.log("New prelude compression ratio of: " & $PRELUDE_RATIO)
|
||||
discard init()
|
||||
|
||||
proc add_to_lp() {.exportc.} =
|
||||
let new_text = document.getElementById("text_input").value
|
||||
|
|
@ -175,13 +177,12 @@ when defined(js) and isMainModule:
|
|||
setLocalStorageItem("local_prelude", existing & "\n" & new_text)
|
||||
else:
|
||||
setLocalStorageItem("local_prelude", new_text)
|
||||
PRELUDE_RATIO = compress_str("")
|
||||
console.log("New prelude compression ratio of: " & $PRELUDE_RATIO)
|
||||
discard init()
|
||||
|
||||
proc do_detect() {.exportc.} =
|
||||
proc do_detect() {.exportc, async.} =
|
||||
let
|
||||
text : string = $document.getElementById("text_input").value
|
||||
var (d, s) = run_on_text_chunked(text)
|
||||
var (d, s) = await run_on_text_chunked(text)
|
||||
var color = "rgba(255, 0, 0, " & $(s.round(3) * 10.0) & ")"
|
||||
if d == "Human":
|
||||
color = "rgba(0, 255, 0, " & $(s.round(3) * 10.0) & ")"
|
||||
|
|
@ -191,17 +192,14 @@ when defined(js) and isMainModule:
|
|||
when defined(extension):
|
||||
proc add_to_lp(text : cstring) {.exportc.} =
|
||||
local_prelude = local_prelude & "\n".cstring & text
|
||||
PRELUDE_RATIO = compress_str("")
|
||||
console.log("New prelude compression ratio of: " & $PRELUDE_RATIO)
|
||||
discard init()
|
||||
|
||||
proc detect_string(s : cstring) : float {.exportc.} =
|
||||
proc detect_string(s : cstring) : Future[float] {.exportc,async.} =
|
||||
# Returns the opacity for the element containing the passed string (higher for human-generated)
|
||||
var (d, s) = run_on_text_chunked($s)
|
||||
var (d, s) = await run_on_text_chunked($s)
|
||||
if d == "Human":
|
||||
return 1.0
|
||||
var opacity = 1.0 - s.round(3) * 10
|
||||
if opacity < 0.0:
|
||||
opacity = 0.0
|
||||
return opacity
|
||||
|
||||
#window.onload = on_load
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ from sklearn.metrics import roc_curve, auc
|
|||
import re
|
||||
from junitparser import JUnitXml
|
||||
|
||||
MODELS = ['zippy', 'roberta', 'gptzero', 'crossplag', 'contentatscale']
|
||||
MODELS = ['zippy-lzma', 'zippy-zlib', 'roberta', 'gptzero', 'crossplag', 'contentatscale']
|
||||
SKIPCASES = ['gpt2', 'gpt3']
|
||||
|
||||
MAX_PER_CASE = 500
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ AI_SAMPLE_DIR = 'samples/llm-generated/'
|
|||
HUMAN_SAMPLE_DIR = 'samples/human-generated/'
|
||||
|
||||
MIN_LEN = 150
|
||||
NUM_JSONL_SAMPLES = 15#500
|
||||
NUM_JSONL_SAMPLES = 500
|
||||
|
||||
ai_files = os.listdir(AI_SAMPLE_DIR)
|
||||
human_files = os.listdir(HUMAN_SAMPLE_DIR)
|
||||
|
|
@ -68,37 +68,37 @@ def test_human_jsonl(i, record_property):
|
|||
record_property("score", str(score))
|
||||
assert classification == 'Human', HUMAN_JSONL_FILE + ':' + str(i.get('id')) + ' (len: ' + str(i.get('length', -1)) + ') is a human-generated sample, misclassified as AI-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
AI_JSONL_FILE = 'samples/xl-1542M.test.jsonl'
|
||||
ai_samples = []
|
||||
with jsonlines.open(AI_JSONL_FILE) as reader:
|
||||
for obj in reader:
|
||||
ai_samples.append(obj)
|
||||
# AI_JSONL_FILE = 'samples/xl-1542M.test.jsonl'
|
||||
# ai_samples = []
|
||||
# with jsonlines.open(AI_JSONL_FILE) as reader:
|
||||
# for obj in reader:
|
||||
# ai_samples.append(obj)
|
||||
|
||||
@pytest.mark.parametrize('i', ai_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_llm_jsonl(i, record_property):
|
||||
res = run_on_text_chunked(i.get('text', ''))
|
||||
if res is None:
|
||||
pytest.skip('Unable to classify')
|
||||
(classification, score) = res
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', AI_JSONL_FILE + ':' + str(i.get('id')) + ' (text: ' + i.get('text', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
# @pytest.mark.parametrize('i', ai_samples[0:NUM_JSONL_SAMPLES])
|
||||
# def test_gpt2_jsonl(i, record_property):
|
||||
# res = run_on_text_chunked(i.get('text', ''))
|
||||
# if res is None:
|
||||
# pytest.skip('Unable to classify')
|
||||
# (classification, score) = res
|
||||
# record_property("score", str(score))
|
||||
# assert classification == 'AI', AI_JSONL_FILE + ':' + str(i.get('id')) + ' (text: ' + i.get('text', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
GPT3_JSONL_FILE = 'samples/GPT-3-175b_samples.jsonl'
|
||||
gpt3_samples = []
|
||||
with jsonlines.open(GPT3_JSONL_FILE) as reader:
|
||||
for o in reader:
|
||||
for l in o.split('<|endoftext|>'):
|
||||
if len(l) >= MIN_LEN:
|
||||
gpt3_samples.append(l)
|
||||
# GPT3_JSONL_FILE = 'samples/GPT-3-175b_samples.jsonl'
|
||||
# gpt3_samples = []
|
||||
# with jsonlines.open(GPT3_JSONL_FILE) as reader:
|
||||
# for o in reader:
|
||||
# for l in o.split('<|endoftext|>'):
|
||||
# if len(l) >= MIN_LEN:
|
||||
# gpt3_samples.append(l)
|
||||
|
||||
@pytest.mark.parametrize('i', gpt3_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_gpt3_jsonl(i, record_property):
|
||||
res = run_on_text_chunked(i)
|
||||
if res is None:
|
||||
pytest.skip('Unable to classify')
|
||||
(classification, score) = res
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', GPT3_JSONL_FILE + ' is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
# @pytest.mark.parametrize('i', gpt3_samples[0:NUM_JSONL_SAMPLES])
|
||||
# def test_gpt3_jsonl(i, record_property):
|
||||
# res = run_on_text_chunked(i)
|
||||
# if res is None:
|
||||
# pytest.skip('Unable to classify')
|
||||
# (classification, score) = res
|
||||
# record_property("score", str(score))
|
||||
# assert classification == 'AI', GPT3_JSONL_FILE[0:250] + ' is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
NEWS_JSONL_FILE = 'samples/news.jsonl'
|
||||
news_samples = []
|
||||
|
|
|
|||
|
|
@ -2,21 +2,24 @@
|
|||
|
||||
import pytest, os, jsonlines, csv
|
||||
from warnings import warn
|
||||
from zippy import run_on_file_chunked, run_on_text_chunked, PRELUDE_STR, LzmaLlmDetector
|
||||
from zippy import run_on_file_chunked, run_on_text_chunked, PRELUDE_STR, LzmaLlmDetector, CompressionEngine, ZlibLlmDetector, ENGINE
|
||||
import zippy
|
||||
|
||||
AI_SAMPLE_DIR = 'samples/llm-generated/'
|
||||
HUMAN_SAMPLE_DIR = 'samples/human-generated/'
|
||||
|
||||
MIN_LEN = 50
|
||||
MIN_LEN = 150
|
||||
NUM_JSONL_SAMPLES = 500
|
||||
|
||||
ai_files = os.listdir(AI_SAMPLE_DIR)
|
||||
human_files = os.listdir(HUMAN_SAMPLE_DIR)
|
||||
|
||||
FUZZINESS = 3
|
||||
CONFIDENCE_THRESHOLD : float = 0.00 # What confidence to treat as error vs warning
|
||||
|
||||
PRELUDE_RATIO = LzmaLlmDetector(prelude_str=PRELUDE_STR).prelude_ratio
|
||||
if ENGINE == CompressionEngine.LZMA:
|
||||
PRELUDE_RATIO = LzmaLlmDetector(prelude_str=PRELUDE_STR).prelude_ratio
|
||||
elif ENGINE == CompressionEngine.ZLIB:
|
||||
PRELUDE_RATIO = ZlibLlmDetector(prelude_str=PRELUDE_STR).prelude_ratio
|
||||
|
||||
def test_training_file(record_property):
|
||||
(classification, score) = run_on_file_chunked('ai-generated.txt')
|
||||
|
|
@ -25,7 +28,7 @@ def test_training_file(record_property):
|
|||
|
||||
@pytest.mark.parametrize('f', human_files)
|
||||
def test_human_samples(f, record_property):
|
||||
(classification, score) = run_on_file_chunked(HUMAN_SAMPLE_DIR + f, fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_file_chunked(HUMAN_SAMPLE_DIR + f, prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
if score > CONFIDENCE_THRESHOLD:
|
||||
assert classification == 'Human', f + ' is a human-generated file, misclassified as AI-generated with confidence ' + str(round(score, 8))
|
||||
|
|
@ -37,7 +40,7 @@ def test_human_samples(f, record_property):
|
|||
|
||||
@pytest.mark.parametrize('f', ai_files)
|
||||
def test_llm_sample(f, record_property):
|
||||
(classification, score) = run_on_file_chunked(AI_SAMPLE_DIR + f, fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_file_chunked(AI_SAMPLE_DIR + f, prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
if score > CONFIDENCE_THRESHOLD:
|
||||
assert classification == 'AI', f + ' is an LLM-generated file, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
|
@ -56,36 +59,36 @@ with jsonlines.open(HUMAN_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', human_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_human_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('text', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('text', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'Human', HUMAN_JSONL_FILE + ':' + str(i.get('id')) + ' (len: ' + str(i.get('length', -1)) + ') is a human-generated sample, misclassified as AI-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
AI_JSONL_FILE = 'samples/xl-1542M.test.jsonl'
|
||||
ai_samples = []
|
||||
with jsonlines.open(AI_JSONL_FILE) as reader:
|
||||
for obj in reader:
|
||||
if obj.get('length', 0) >= MIN_LEN:
|
||||
ai_samples.append(obj)
|
||||
# AI_JSONL_FILE = 'samples/xl-1542M.test.jsonl'
|
||||
# ai_samples = []
|
||||
# with jsonlines.open(AI_JSONL_FILE) as reader:
|
||||
# for obj in reader:
|
||||
# if obj.get('length', 0) >= MIN_LEN:
|
||||
# ai_samples.append(obj)
|
||||
|
||||
@pytest.mark.parametrize('i', ai_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_gpt2_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('text', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', AI_JSONL_FILE + ':' + str(i.get('id')) + ' (text: ' + i.get('text', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
# @pytest.mark.parametrize('i', ai_samples[0:NUM_JSONL_SAMPLES])
|
||||
# def test_gpt2_jsonl(i, record_property):
|
||||
# (classification, score) = run_on_text_chunked(i.get('text', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
# record_property("score", str(score))
|
||||
# assert classification == 'AI', AI_JSONL_FILE + ':' + str(i.get('id')) + ' (text: ' + i.get('text', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
GPT3_JSONL_FILE = 'samples/GPT-3-175b_samples.jsonl'
|
||||
gpt3_samples = []
|
||||
with jsonlines.open(GPT3_JSONL_FILE) as reader:
|
||||
for o in reader:
|
||||
for l in o.split('<|endoftext|>'):
|
||||
if len(l) >= MIN_LEN:
|
||||
gpt3_samples.append(l)
|
||||
# GPT3_JSONL_FILE = 'samples/GPT-3-175b_samples.jsonl'
|
||||
# gpt3_samples = []
|
||||
# with jsonlines.open(GPT3_JSONL_FILE) as reader:
|
||||
# for o in reader:
|
||||
# for l in o.split('<|endoftext|>'):
|
||||
# if len(l) >= MIN_LEN:
|
||||
# gpt3_samples.append(l)
|
||||
|
||||
@pytest.mark.parametrize('i', gpt3_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_gpt3_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i, fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', GPT3_JSONL_FILE + ' is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
# @pytest.mark.parametrize('i', gpt3_samples[0:NUM_JSONL_SAMPLES])
|
||||
# def test_gpt3_jsonl(i, record_property):
|
||||
# (classification, score) = run_on_text_chunked(i, prelude_ratio=PRELUDE_RATIO)
|
||||
# record_property("score", str(score))
|
||||
# assert classification == 'AI', GPT3_JSONL_FILE + ' is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
NEWS_JSONL_FILE = 'samples/news.jsonl'
|
||||
news_samples = []
|
||||
|
|
@ -95,13 +98,13 @@ with jsonlines.open(NEWS_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', news_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_humannews_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('human', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('human', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'Human', NEWS_JSONL_FILE + ' is a human-generated sample, misclassified as AI-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
@pytest.mark.parametrize('i', news_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_chatgptnews_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('chatgpt', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('chatgpt', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', NEWS_JSONL_FILE + ' is a AI-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
|
|
@ -114,7 +117,7 @@ with jsonlines.open(CHEAT_HUMAN_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', ch_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_cheat_human_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'Human', CHEAT_HUMAN_JSONL_FILE + ':' + str(i.get('id')) + ' [' + str(len(i.get('abstract', ''))) + '] (title: ' + i.get('title', "").replace('\n', ' ')[:15] + ') is a human-generated sample, misclassified as AI-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
|
|
@ -127,7 +130,7 @@ with jsonlines.open(CHEAT_GEN_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', cg_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_cheat_generation_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', CHEAT_GEN_JSONL_FILE + ':' + str(i.get('id')) + ' (title: ' + i.get('title', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
|
|
@ -140,7 +143,7 @@ with jsonlines.open(CHEAT_POLISH_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', cp_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_cheat_polish_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', CHEAT_POLISH_JSONL_FILE + ':' + str(i.get('id')) + ' (title: ' + i.get('title', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
|
|
@ -153,7 +156,7 @@ with jsonlines.open(CHEAT_VICUNAGEN_JSONL_FILE) as reader:
|
|||
|
||||
@pytest.mark.parametrize('i', vg_samples[0:NUM_JSONL_SAMPLES])
|
||||
def test_vicuna_generation_jsonl(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('abstract', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == 'AI', CHEAT_VICUNAGEN_JSONL_FILE + ':' + str(i.get('id')) + ' (title: ' + i.get('title', "").replace('\n', ' ')[:50] + ') is an LLM-generated sample, misclassified as human-generated with confidence ' + str(round(score, 8))
|
||||
|
||||
|
|
@ -167,12 +170,12 @@ with open(GPTZERO_EVAL_FILE) as fp:
|
|||
|
||||
@pytest.mark.parametrize('i', list(filter(lambda x: x.get('Label') == 'Human', ge_samples[0:NUM_JSONL_SAMPLES])))
|
||||
def test_gptzero_eval_dataset_human(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('Document', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('Document', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == i.get('Label'), GPTZERO_EVAL_FILE + ':' + str(i.get('Index')) + ' was misclassified with confidence ' + str(round(score, 8))
|
||||
|
||||
@pytest.mark.parametrize('i', list(filter(lambda x: x.get('Label') == 'AI', ge_samples[0:NUM_JSONL_SAMPLES])))
|
||||
def test_gptzero_eval_dataset_ai(i, record_property):
|
||||
(classification, score) = run_on_text_chunked(i.get('Document', ''), fuzziness=FUZZINESS, prelude_ratio=PRELUDE_RATIO)
|
||||
(classification, score) = run_on_text_chunked(i.get('Document', ''), prelude_ratio=PRELUDE_RATIO)
|
||||
record_property("score", str(score))
|
||||
assert classification == i.get('Label'), GPTZERO_EVAL_FILE + ':' + str(i.get('Index')) + ' was misclassified with confidence ' + str(round(score, 8))
|
||||
|
|
|
|||
112
zippy.py
112
zippy.py
|
|
@ -5,12 +5,21 @@
|
|||
# Author: Jacob Torrey <jacob@thinkst.com>
|
||||
|
||||
import lzma, argparse, os, itertools
|
||||
from zlib import compressobj, Z_FINISH
|
||||
import re, sys
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import Enum
|
||||
from typing import List, Optional, Tuple, TypeAlias
|
||||
from multiprocessing import Pool, cpu_count
|
||||
|
||||
Score : TypeAlias = tuple[str, float]
|
||||
|
||||
class CompressionEngine(Enum):
|
||||
LZMA = 1
|
||||
ZLIB = 2
|
||||
|
||||
ENGINE : CompressionEngine = CompressionEngine.ZLIB
|
||||
|
||||
def clean_text(s : str) -> str:
|
||||
'''
|
||||
Removes formatting and other non-content data that may skew compression ratios (e.g., duplicate spaces)
|
||||
|
|
@ -32,9 +41,61 @@ PRELUDE_FILE : str = 'ai-generated.txt'
|
|||
with open(PRELUDE_FILE, 'r') as fp:
|
||||
PRELUDE_STR = clean_text(fp.read())
|
||||
|
||||
class LzmaLlmDetector:
|
||||
class AIDetector(ABC):
|
||||
'''
|
||||
Base class for AI detection
|
||||
'''
|
||||
@abstractmethod
|
||||
def score_text(self, sample : str) -> Optional[Score]:
|
||||
pass
|
||||
|
||||
class ZlibLlmDetector(AIDetector):
|
||||
'''Class providing functionality to attempt to detect LLM/generative AI generated text using the zlib compression algorithm'''
|
||||
def __init__(self, prelude_file : Optional[str] = None, prelude_str : Optional[str] = None, prelude_ratio : Optional[float] = None):
|
||||
self.PRESET = 9
|
||||
self.WBITS = -15
|
||||
self.prelude_ratio = 0.0
|
||||
if prelude_ratio != None:
|
||||
self.prelude_ratio = prelude_ratio
|
||||
|
||||
if prelude_file != None:
|
||||
with open(prelude_file) as fp:
|
||||
self.prelude_str = fp.read()
|
||||
self.prelude_ratio = self._compress(self.prelude_str)
|
||||
|
||||
if prelude_str != None:
|
||||
self.prelude_str = prelude_str
|
||||
self.prelude_ratio = self._compress(self.prelude_str)
|
||||
|
||||
def _compress(self, s : str) -> float:
|
||||
orig_len = len(s.encode())
|
||||
c = compressobj(level=self.PRESET, wbits=self.WBITS, memLevel=9)
|
||||
bytes = c.compress(s.encode())
|
||||
bytes += c.flush(Z_FINISH)
|
||||
c_len = len(bytes)
|
||||
#c_len = len(compress(s.encode(), level=self.PRESET, wbits=self.WBITS))
|
||||
return c_len / orig_len
|
||||
|
||||
def score_text(self, sample: str) -> Score | None:
|
||||
'''
|
||||
Returns a tuple of a string (AI or Human) and a float confidence (higher is more confident) that the sample was generated
|
||||
by either an AI or human. Returns None if it cannot make a determination
|
||||
'''
|
||||
if self.prelude_ratio == 0.0:
|
||||
return None
|
||||
sample_score = self._compress(self.prelude_str + sample)
|
||||
#print(str((self.prelude_ratio, sample_score)))
|
||||
delta = self.prelude_ratio - sample_score
|
||||
determination = 'AI'
|
||||
if delta < 0:
|
||||
determination = 'Human'
|
||||
|
||||
return (determination, abs(delta * 100))
|
||||
|
||||
|
||||
class LzmaLlmDetector(AIDetector):
|
||||
'''Class providing functionality to attempt to detect LLM/generative AI generated text using the LZMA compression algorithm'''
|
||||
def __init__(self, prelude_file : Optional[str] = None, fuzziness_digits : int = 3, prelude_str : Optional[str] = None, prelude_ratio : Optional[float] = None) -> None:
|
||||
def __init__(self, prelude_file : Optional[str] = None, prelude_str : Optional[str] = None, prelude_ratio : Optional[float] = None) -> None:
|
||||
'''Initializes a compression with the passed prelude file, and optionally the number of digits to round to compare prelude vs. sample compression'''
|
||||
self.PRESET : int = 2
|
||||
self.comp = lzma.LZMACompressor(preset=self.PRESET)
|
||||
|
|
@ -43,7 +104,6 @@ class LzmaLlmDetector:
|
|||
self.prelude_ratio : float = 0.0
|
||||
if prelude_ratio != None:
|
||||
self.prelude_ratio = prelude_ratio
|
||||
self.FUZZINESS_THRESHOLD = fuzziness_digits
|
||||
self.SHORT_SAMPLE_THRESHOLD : int = 350 # What sample length is considered "short"
|
||||
|
||||
if prelude_file != None:
|
||||
|
|
@ -102,39 +162,39 @@ class LzmaLlmDetector:
|
|||
if self.prelude_ratio == 0.0:
|
||||
return None
|
||||
(prelude_score, sample_score) = self.get_compression_ratio(sample)
|
||||
#print(str((prelude_score, sample_score)))
|
||||
print(str((self.prelude_ratio, sample_score)))
|
||||
delta = prelude_score - sample_score
|
||||
determination = 'AI'
|
||||
if delta < 0:
|
||||
determination = 'Human'
|
||||
|
||||
# If the sample doesn't 'move the needle', it's very close
|
||||
# if round(delta, self.FUZZINESS_THRESHOLD) == 0 and len(sample) >= self.SHORT_SAMPLE_THRESHOLD:
|
||||
# #print('Sample len to default to AI: ' + str(len(sample)))
|
||||
# determination = 'AI'
|
||||
# if round(delta, self.FUZZINESS_THRESHOLD) == 0 and len(sample) < self.SHORT_SAMPLE_THRESHOLD:
|
||||
# #print('Sample len to default to Human: ' + str(len(sample)))
|
||||
# determination = 'Human'
|
||||
#if abs(delta * 100) < .1 and determination == 'AI':
|
||||
# print("Very low-confidence determination of: " + determination)
|
||||
return (determination, abs(delta * 100))
|
||||
|
||||
def run_on_file(filename : str, fuzziness : int = 3) -> Optional[Score]:
|
||||
def run_on_file(filename : str) -> Optional[Score]:
|
||||
'''Given a filename (and an optional number of decimal places to round to) returns the score for the contents of that file'''
|
||||
with open(filename, 'r') as fp:
|
||||
l = LzmaLlmDetector(PRELUDE_FILE, fuzziness)
|
||||
if ENGINE == CompressionEngine.LZMA:
|
||||
l = LzmaLlmDetector(prelude_file=PRELUDE_FILE)
|
||||
elif ENGINE == CompressionEngine.ZLIB:
|
||||
l = ZlibLlmDetector(prelude_file=PRELUDE_FILE)
|
||||
txt = fp.read()
|
||||
#print('Calculating score for input of length ' + str(len(txt)))
|
||||
return l.score_text(txt)
|
||||
|
||||
def _score_chunk(c : str, fuzziness : int = 3, prelude_file : Optional[str] = None, prelude_ratio : Optional[float] = None) -> Score:
|
||||
def _score_chunk(c : str, prelude_file : Optional[str] = None, prelude_ratio : Optional[float] = None) -> Score:
|
||||
if prelude_file != None:
|
||||
l = LzmaLlmDetector(fuzziness_digits=fuzziness, prelude_file=prelude_file)
|
||||
if ENGINE == CompressionEngine.LZMA:
|
||||
l = LzmaLlmDetector(prelude_file=prelude_file)
|
||||
if ENGINE == CompressionEngine.ZLIB:
|
||||
l = ZlibLlmDetector(prelude_file=prelude_file)
|
||||
else:
|
||||
l = LzmaLlmDetector(fuzziness_digits=fuzziness, prelude_str=PRELUDE_STR, prelude_ratio=prelude_ratio)
|
||||
if ENGINE == CompressionEngine.LZMA:
|
||||
l = LzmaLlmDetector(prelude_str=PRELUDE_STR, prelude_ratio=prelude_ratio)
|
||||
if ENGINE == CompressionEngine.ZLIB:
|
||||
l = ZlibLlmDetector(prelude_str=PRELUDE_STR, prelude_ratio=prelude_ratio)
|
||||
return l.score_text(c)
|
||||
|
||||
def run_on_file_chunked(filename : str, chunk_size : int = 1500, fuzziness : int = 3, prelude_ratio : Optional[float] = None) -> Optional[Score]:
|
||||
def run_on_file_chunked(filename : str, chunk_size : int = 1500, prelude_ratio : Optional[float] = None) -> Optional[Score]:
|
||||
'''
|
||||
Given a filename (and an optional chunk size and number of decimal places to round to) returns the score for the contents of that file.
|
||||
This function chunks the file into at most chunk_size parts to score separately, then returns an average. This prevents a very large input
|
||||
|
|
@ -142,9 +202,9 @@ def run_on_file_chunked(filename : str, chunk_size : int = 1500, fuzziness : int
|
|||
'''
|
||||
with open(filename, 'r') as fp:
|
||||
contents = fp.read()
|
||||
return run_on_text_chunked(contents, chunk_size, fuzziness=fuzziness, prelude_ratio=prelude_ratio)
|
||||
return run_on_text_chunked(contents, chunk_size, prelude_ratio=prelude_ratio)
|
||||
|
||||
def run_on_text_chunked(s : str, chunk_size : int = 1500, fuzziness : int = 3, prelude_file : Optional[str] = None, prelude_ratio : Optional[float] = None) -> Optional[Score]:
|
||||
def run_on_text_chunked(s : str, chunk_size : int = 1500, prelude_file : Optional[str] = None, prelude_ratio : Optional[float] = None) -> Optional[Score]:
|
||||
'''
|
||||
Given a string (and an optional chunk size and number of decimal places to round to) returns the score for the passed string.
|
||||
This function chunks the input into at most chunk_size parts to score separately, then returns an average. This prevents a very large input
|
||||
|
|
@ -163,11 +223,11 @@ def run_on_text_chunked(s : str, chunk_size : int = 1500, fuzziness : int = 3, p
|
|||
scores = []
|
||||
if len(chunks) > 2:
|
||||
with Pool(cpu_count()) as pool:
|
||||
for r in pool.starmap(_score_chunk, zip(chunks, itertools.repeat(fuzziness), itertools.repeat(prelude_file), itertools.repeat(prelude_ratio))):
|
||||
for r in pool.starmap(_score_chunk, zip(chunks, itertools.repeat(prelude_file), itertools.repeat(prelude_ratio))):
|
||||
scores.append(r)
|
||||
else:
|
||||
for c in chunks:
|
||||
scores.append(_score_chunk(c, fuzziness=fuzziness, prelude_file=prelude_file, prelude_ratio=prelude_ratio))
|
||||
scores.append(_score_chunk(c, prelude_file=prelude_file, prelude_ratio=prelude_ratio))
|
||||
ssum : float = 0.0
|
||||
for i, s in enumerate(scores):
|
||||
if s[0] == 'AI':
|
||||
|
|
@ -183,10 +243,16 @@ def run_on_text_chunked(s : str, chunk_size : int = 1500, fuzziness : int = 3, p
|
|||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("-e", choices=['zlib', 'lzma'], help='Which compression engine to use: lzma or zlib', default='lzma', required=False)
|
||||
group = parser.add_mutually_exclusive_group()
|
||||
group.add_argument("-s", help='Read from stdin until EOF is reached instead of from a file', required=False, action='store_true')
|
||||
group.add_argument("sample_files", nargs='*', help='Text file(s) containing the sample to classify', default="")
|
||||
args = parser.parse_args()
|
||||
if args.e:
|
||||
if args.e == 'lzma':
|
||||
ENGINE = CompressionEngine.LZMA
|
||||
elif args.e == 'zlib':
|
||||
ENGINE = CompressionEngine.ZLIB
|
||||
if args.s:
|
||||
print(str(run_on_text_chunked(''.join(list(sys.stdin)))))
|
||||
elif len(args.sample_files) == 0:
|
||||
|
|
|
|||
Ładowanie…
Reference in New Issue